Building Vision Transformers with PyTorch
Sept 2, 2024
Hey there! Ever wondered how those super smart AI models understand images? Like, how can a computer look at a picture of a cat and be like, "Yo, that's a cat!"? Well, my friend, today we're building one from scratch using PyTorch!
You might've heard of Transformers in the context of Natural Language Processing (NLP). They're the tech behind those chatbots and language models that spit out some pretty impressive text. But here's the twist: what if we used that same technology on images? Enter Vision Transformers.
Here is the link to the "An Image is worth 16*16 words" Vision Transformer research paper.
Instead of reading words like in NLP, we're gonna slice up images into tiny patches, treat them like words, and feed them into a Transformer. By the end, we'll have a model that can look at an image and tell us what's in it. Cool, right?
The Core Structure: Breaking It Down
Our Vision Transformer is like a layered cake, with each layer doing something special. Let's go through each layer and see how it all comes together:
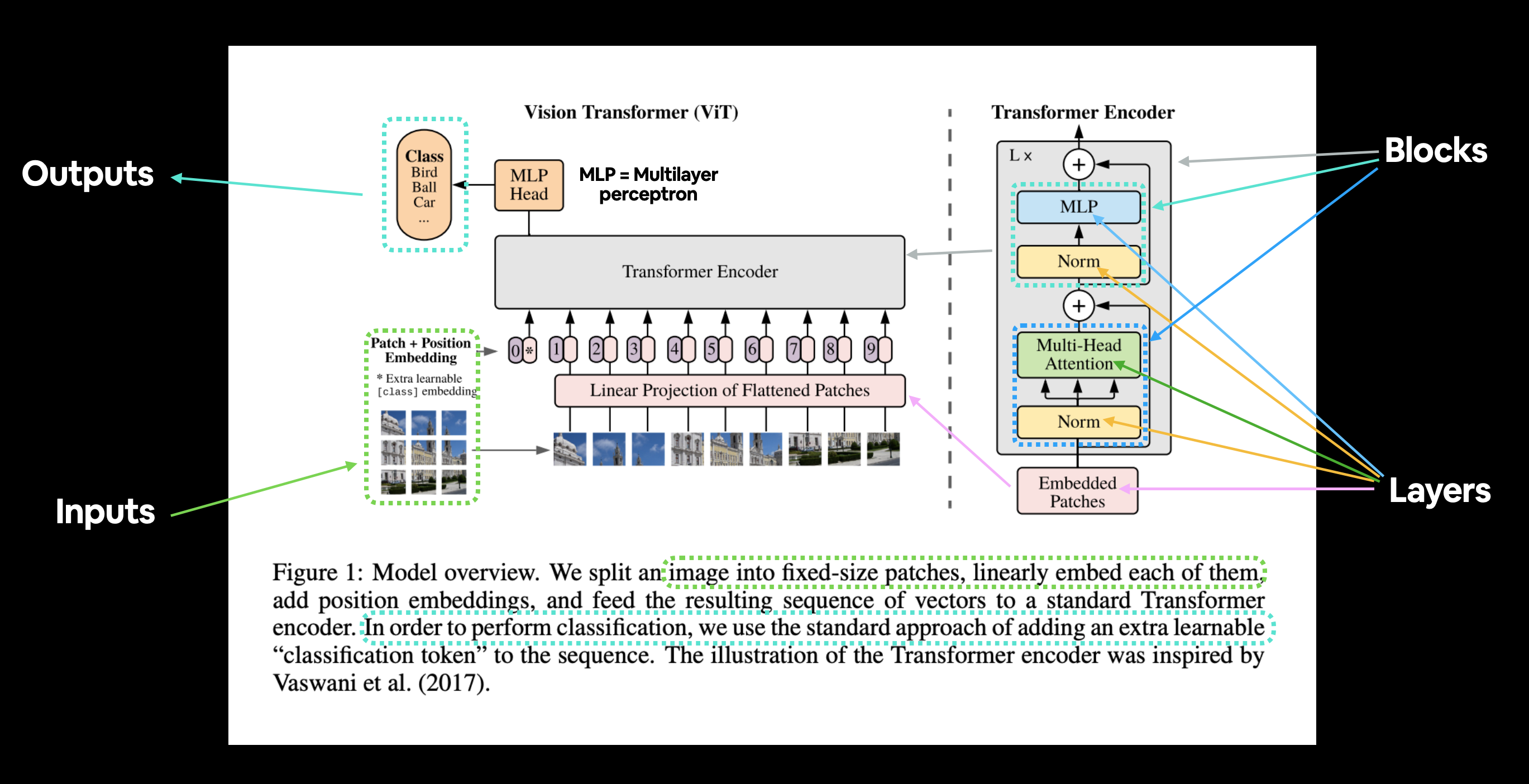
1. Patch + Position Embedding: The Foundation
First up, we need to break our image into patches. Think of each patch as a small piece of the puzzle. But the Transformer needs to know the order of these pieces, so we add some position info to each patch—just like numbering puzzle pieces. This helps the model understand the layout of the image.

2. Linear Projection: Turning Patches into Embeddings
Next, we convert these patches into embeddings. What's an embedding, you ask? It's a fancy way of turning raw image data into a format that the model can learn from. Imagine the patches going through a cool filter that makes them smarter!

3. Norm: Keeping Things Regular
Layer Normalization, or "LayerNorm", is like that friend who keeps you grounded. It regularizes the model, making sure it doesn't get too carried away with any one piece of information. This helps prevent overfitting, where the model gets too good at the training data but flops in the real world.
4. Multi-Head Attention: The Gossip Layer
Now we get to the juicy part—Multi-Head Self-Attention (MSA). This layer is like a bunch of friends in a group chat. They're all talking to each other, sharing gossip (information), and making sure everyone's in the loop. Each head in this layer looks at the image from a different angle, ensuring that no detail is missed.
5. MLP: The Brain Power
After all that chatting, we need to do some serious thinking. Enter the Multilayer Perceptron (MLP), which is just a fancy way of saying "a bunch of neurons working together." This layer processes the information, learns patterns, and makes decisions. It's the brain of our Transformer.
6. Transformer Encoder: Stack 'Em Up
The Transformer Encoder is where things get stacked—literally. It's a combination of all the layers above, repeated multiple times. Think of it like stacking multiple burgers on top of each other to make a giant, delicious burger tower. Each layer adds more flavor (or in our case, more learning).

7. MLP Head: The Final Answer
Finally, after all that hard work, we need to get the answer. The MLP Head is the final layer that takes all the learned features and says, "Okay, based on everything I've seen, this image is a dog!" Or a cat. Or whatever's in the image.
Let's Code This Bad Boy
Here's how you can implement a Vision Transformer from scratch using PyTorch:
import torch
import torch.nn as nn
class PatchEmbedding(nn.Module):
"""Turns a 2D input image into a 1D sequence learnable embedding vector.
Args:
in_channels (int): Number of color channels for the input images. Defaults to 3.
patch_size (int): Size of patches to convert input image into. Defaults to 16.
embedding_dim (int): Size of embedding to turn image into. Defaults to 768.
"""
# 2. Initialize the class with appropriate variables
def __init__(self,
in_channels:int=3,
patch_size:int=16,
embedding_dim:int=768):
super().__init__()
self.patch_size = patch_size
# 3. Create a layer to turn an image into patches
self.patcher = nn.Conv2d(in_channels=in_channels,
out_channels=embedding_dim,
kernel_size=patch_size,
stride=patch_size,
padding=0)
# 4. Create a layer to flatten the patch feature maps into a single dimension
self.flatten = nn.Flatten(start_dim=2, # only flatten the feature map dimensions into a single vector
end_dim=3)
# 5. Define the forward method
def forward(self, x):
# Create assertion to check that inputs are the correct shape
image_resolution = x.shape[-1]
assert image_resolution % self.patch_size == 0, f"Input image size must be divisble by patch size, image shape: {image_resolution}, patch size: {self.patch_size}"
# Perform the forward pass
x_patched = self.patcher(x)
x_flattened = self.flatten(x_patched)
# 6. Make sure the output shape has the right order
return x_flattened.permute(0, 2, 1) #permuting to change the order of dimension
#main function
class ViT(nn.Module):
def __init__(self,
img_size = 224,
in_channels=3, #table 3
patch_size = 16,
embedding_dim = 768,
dropout= 0.1,
mlp_size = 3072,
num_transformers_layers = 12,
num_heads = 12,
num_classes=1000):
super().__init__()
assert img_size % patch_size == 0 , "Image size should be divisible by patch size"
#create patch embedding
self.patch_embedding = PatchEmbedding(in_channels=in_channels,
patch_size=patch_size,
embedding_dim=embedding_dim)
#create class token
self.class_token = nn.Parameter(torch.randn(1,1,embedding_dim),
requires_grad=True)
#create positional embedding
num_patches = (img_size * img_size) // patch_size ** 2 # N= HW/p*3
self.positional_embedding = nn.Parameter(torch.randn(1, num_patches + 1 ,embedding_dim))
#create patch + positional embedding dropout
self.embedding_dropout = nn.Dropout(p=dropout)
#create stacked Transformer Encoder layes
self.transformer_encoder = nn.TransformerEncoder(encoder_layer= nn.TransformerEncoderLayer(d_model=embedding_dim,
activation='gelu',
batch_first=True,
norm_first=True,
nhead=num_heads,
dim_feedforward=mlp_size),
num_layers=num_transformers_layers)
# create MLP heads
self.mlp_head = nn.Sequential(
nn.LayerNorm(normalized_shape=embedding_dim),
nn.Linear(in_features=embedding_dim,
out_features=num_classes)
)
def forward(self, x):
#batch size
batch_size = x.shape[0]
#patch embedding
x = self.patch_embedding(x)
# Create class token embedding and expand it to match the batch size (equation 1)
class_token = self.class_token.expand(batch_size, -1, -1) # "-1" means to infer the dimension
# Concat class embedding and patch embedding (equation 1)
x = torch.cat((class_token, x), dim=1)
# Add positional embedding to patch embedding with class token
x = self.positional_embedding + x
# droput on patch + positional embedding
x = self.embedding_dropout(x)
# Pass embedding through Transformer Encoder stack
x = self.transformer_encoder(x)
# Pass 0th index of x through MLP head
x = self.mlp_head(x[:,0])
return x
Wrapping Up
Vision Transformers are powerful tools, capable of understanding images in ways that were previously unimaginable. By splitting images into patches and treating them like words in a sentence, we can make use the power of Transformers in a whole new way. you can find the complete implementation here.
References
- Daniel Brouke learnpytorch.io.
- Official Pytorch documentation.